
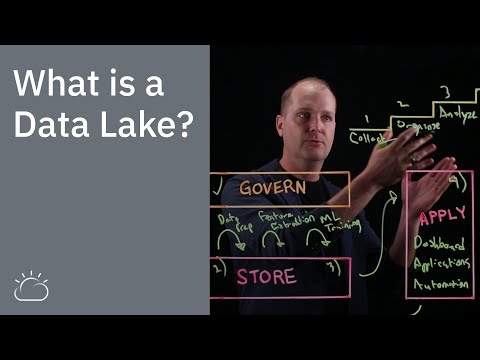
A data lake is a centralised storage repository that can hold vast amounts of raw data in its native format until it is needed for analysis.
Unlike traditional data warehouses that require data to be structured and processed before storage, data lakes can accommodate structured, semi-structured and unstructured data from a variety of sources.
In essence, this makes data lakes perfect for organisations that have huge portfolios of data and need flexible solutions when it comes to storage, even if they are unsure how they will use that data in the future.
In 2025, data lakes have become the darling of AI companies, whose technologies simply would not work without massive amounts of data.
In recent years the maturation of the 'lakehouse' architecture, a hybrid model that fuses the raw flexibility of data lakes with the transactional integrity of data warehouses, has been especially important to the AI sector.
Modern AI requires both colossal scale and unwavering data reliability, a combination that traditional architecture simply cannot provide.
In this week’s Top 10, we dive right into data lakes, spotlighting some of the best examples in terms of architecture and application.
10. Dremio
Founded: 2015
HQ: Santa Clara, California, USA
CEO: Sendur Sellakumar
Notable feature: A high-performance SQL query engine that queries data directly on the lake, eliminating data copies.
Dremio positions itself as the "easy and open data lakehouse", focusing on fast performance directly on data lake storage, all without the need for complex data movement.
Its standout feature is a high-performance SQL engine that makes data accessible to business intelligence analysts using familiar tools like Tableau.
By creating 'reflections' (a terms for optimised data materialisations), Dremio is able to simplify the path from raw data to insight, challenging more complex, pipeline-heavy architectures and appealing to organisations that prioritise self-service analytics and speed.
9. Teradata Vantage
Foudned: 1979 (Company founding)
HQ: San Diego, California, USA
CEO: Steve McMillan
Notable feature: Massively Parallel Processing (MPP) architecture adapted for hybrid cloud and data lake analytics.

A titan of the traditional data warehousing world, Teradata has evolved its offering with Vantage, a platform designed for the hybrid, multi-cloud era.
In this partnership, Vantage has integrated its legendary Massively Parallel Processing (MPP) engine with Teradata's data lake sources, allowing it to query data in place, whether on-premises or in the cloud.
By embracing open formats like Apache Iceberg and Delta Lake, Teradata is able to give its extensive enterprise client base a pathway to modernise their analytics without abandoning decades of investment in its robust ecosystem.
8. Oracle Cloud Infrastructure (OCI) Data Lake
Founded: 2016 (OCI initial release)
HQ: Austin, Texas, USA
CEO: Clay Magouyrk and Mike Sicilia
Notable feature: Deep integration with Oracle Autonomous Data Warehouse for a unified lakehouse experience.

Oracle's deep roots in the enterprise world are a big part of its data lake solution, which is built on Oracle Cloud infrastructure.
Its strength lies in its seamless integration with Oracle's vast portfolio, particularly the Autonomous Data Warehouse.
This allows businesses to create a unified data platform where data flows from transactional systems into the data lake and on to curated analytics environments.
With tools for batch and real-time ingestion, a managed Apache Spark service, and deep AI/ML integration, OCI presents a compelling, all-in-one proposition for its massive existing customer base.
7. IBM watsonx.data
Founded: 2023
HQ: Armonk, New York, USA
CEO: Arvind Krishna
Notable feature: A fit-for-purpose data store built on an open lakehouse architecture specifically to scale AI workloads.
IBM's entry is purpose-built for the AI era. Watsonx.data is a data store founded on an open lakehouse architecture, designed to scale AI workloads wherever the data resides.
Its data lake system is able to separate compute, storage and metadata, offering flexibility across all kinds of hybrid cloud environments.
By integrating multiple query engines like Presto and Spark – and embracing open formats like Iceberg – IBM has managed to provide a single point of access for both business intelligence and the demanding data preparation and governance tasks required for enterprise-grade Gen AI.
6. Cloudera Data Platform (CDP)
Founded: 2008 (Company founding)
HQ: Santa Clara, California, USA
CEO: Charles Sansbury
Notable feature: A unified data fabric for hybrid and multi-cloud environments with consistent, enterprise-grade security and governance (SDX).
Forged from the merger of big data pioneers Cloudera and Hortonworks, the Cloudera Data Platform (CDP) is one of the most impressive leaders in hybrid and on-premises data lakes.
CDP provides a unified data fabric that extends from private data centres to public clouds, offering consistent security and governance via its Shared Data Experience (SDX).
This makes it the platform of choice for large, regulated industries like finance and healthcare that require granular control over their data, regardless of its physical location, while still leveraging cloud-native analytics.
5. Google Cloud BigLake
Founded: 2022
HQ: Mountain View, California, USA
CEO: Sundar Pichai
Notable feature: A unified storage engine for multi-cloud analytics, allowing queries across GCP, AWS and Azure without data movement.

Google's BigLake is an elegant solution to the multi-format, multi-cloud data challenge.
It acts as a unified storage engine that allows organisations to analyse data across Google Cloud, AWS and Azure without moving or duplicating it.
By presenting data from various cloud object stores and open formats (like Parquet and Iceberg) as unified tables, BigLake enables powerful, cross-platform analytics using familiar tools like BigQuery.
This approach provides fine-grained security and accelerates AI initiatives by breaking down the silos that traditionally separate cloud data ecosystems.
4. Microsoft Azure Data Lake Storage (ADLS)
Founded: 2019 (Gen2 GA)
HQ: Redmond, Washington, USA
CEO: Satya Nadella
Notable feature: A hierarchical namespace optimised for big data analytics performance, tightly integrated with the entire Azure ecosystem.

Microsoft's Azure Data Lake Storage (ADLS) is the foundational data lake for enterprises deeply embedded in the Azure ecosystem.
Built on Azure Blob Storage, its key innovation is a hierarchical namespace that dramatically improves performance for big data analytics workloads.
ADLS is more than a storage layer, though. It is deeply integrated with the entire suite of Azure services, including Synapse Analytics, Databricks and Azure Machine Learning.
This tight integration makes it an incredibly powerful and scalable foundation for building end-to-end AI applications within a single, cohesive cloud environment.
3. Snowflake
Founded: 2012
HQ: Bozeman, Montana, USA
CEO: Sridhar Ramaswamy
Notable feature: A multi-cluster, shared data architecture that decouples storage and compute for near-infinite, concurrent scalability.

Snowflake is a company that has revolutionised the data warehouse with its cloud-native architecture, and it is now aggressively expanding to dominate the data lake sphere too.
Its platform brilliantly decouples storage from compute, allowing teams to scale resources independently and concurrently, eliminating resource contention.
While historically more proprietary, Snowflake is rapidly embracing open formats, and its Snowpark product allows data scientists to run Python, Java and Scala code directly on the data.
Renowned for its simplicity, performance and powerful data-sharing capabilities, Snowflake is making a compelling case to be the single, unified platform for all of an organisation's data, from structured BI to unstructured AI workloads.
2. Databricks Delta Lake
Founded: 2019 (Delta Lake open-sourced)
HQ: San Francisco, California, USA
CEO: Ali Ghodsi
Notable feature: An open-source storage layer providing ACID transactions and scalable metadata, forming the foundation of the modern lakehouse.

Born from the creators of Apache Spark, Databricks is the architect of the modern data lakehouse as we know it.
Its core is Delta Lake, an open-source storage layer that brings ACID transactions, scalable metadata handling and time travel capabilities to data stored in cloud object storage.
This system transforms unreliable data lakes into a single source of truth for both streaming and batch analytics.
The Databricks platform is purpose-built for the most demanding AI and machine learning workloads, providing a collaborative environment for data engineers and data scientists to build, train and deploy models at massive scale, all while championing open standards.
1. Amazon Web Services (S3 & Lake Formation)
Founded: 2006 (Amazon S3 launch)
HQ: Seattle, Washington, USA
CEO: Matt Garman
Notable feature: The combination of Amazon S3's foundational object storage with AWS Lake Formation for simplified, centralised data lake governance.

It's arguable that AWS is the foundational layer upon which much of the market is built.
With over a million data lakes running on its infrastructure, Amazon S3 is the de facto standard for cloud object storage, offering unparalleled scalability, durability and cost-effectiveness.
The true power, however, comes from the surrounding ecosystem.
AWS Lake Formation simplifies the complex tasks of building, securing and governing data lakes, while services like AWS Glue for ETL, Athena for serverless queries and SageMaker for machine learning integrate seamlessly, creating an unmatched end-to-end platform for data and AI.




