The Fairness Frontier: Ethical Challenges in AI Development

As the reach of artificial intelligence (AI) extends across various sectors—from healthcare and law enforcement to education and employment—so too does the critical scrutiny of its ethical dimensions, particularly concerning bias and fairness.
The harm caused by biased AI systems to users can manifest in various direct and indirect ways.
Directly, such systems might deny individuals opportunities or services based on unfair criteria—such as loans, job interviews, or medical care—reinforcing existing societal inequities. Indirectly, the perpetuation of stereotypes and biases can further marginalise vulnerable groups, contributing to a broader societal climate of exclusion and discrimination.
For example, facial recognition technologies have been criticised for higher error rates when identifying individuals from certain racial or ethnic groups, leading to potentially false accusations or unwarranted surveillance.
An additional consequence could be reputational damage to developers and organisations arising from public and stakeholder perception that they are either complicit in, or negligent about, the perpetuation of bias and unfairness through their technologies. This can lead to a loss of trust and in some cases legal and regulatory repercussions.
Defining AI fairness
As awareness around AI ethics grows, the failure to address these issues proactively can put developers at a competitive disadvantage, impacting their brand and financial standing. The backlash received by Amazon over biases in its AI recruiting tool exemplifies how such issues can come to light and affect a company's reputation.
Defining bias and fairness within AI systems is a vital but non-trivial challenge, due to the multifaceted nature of these concepts. In simple terms, fairness in AI refers to the idea that AI systems should treat everyone equally, without bias against any group of people. This means the system's decisions or predictions should not favour one demographic subgroup over another, especially in critical areas like hiring, lending, or healthcare. Fairness tries to ensure that all individuals, regardless of their background, have the same opportunities when interacting with AI technologies.
However, to ensure real-world equity in practice, these simple principles require an implementation that is context-specific and nuanced across the many varied domains in which AI systems are applied. For example, they may take concrete expression differently when applied to a generative AI model, such as a large language model (LLM), and when applied to a predictive AI model such as a classifier.
Although generative AI models are currently at the forefront of many aspects of AI, the bread and butter of AI remains in predictive systems, and work on quantitative definitions of fairness are most advanced in that area of AI. The academic community has proposed a variety of definitions, intended to capture different aspects of bias and fairness, and reflecting the broad spectrum of ethical considerations in AI development and application. Some of these definitions have been gathered in international standards, such as ISO/IEC TR 24027:2021.
Concretely, many of these fairness definitions are quantitatively expressed by requiring the equality of various metrics across different demographic subgroups; metrics that are derived from the AI model's confusion matrix (see Sidebar 1). As an example, the Equality of Opportunity criterion, detailed in ISO/IEC TR 24027:2021 Clause 7.4, emphasises the need for equal True Positive Rates (TPR) between subgroups. Similarly, the Predictive Equality criterion (Clause 7.6) underlines the importance of having equal False Positive Rates (FPR) between subgroups.
Sidebar 1: The Confusion Matrix and some derived metrics
A confusion matrix for classification helps evaluate the performance of an AI model by comparing its predictions against actual outcomes.
In a binary classification problem, outcomes are classified as Positive (P) or Negative (N). The matrix consists of four elements: True Positives (TP), where the model correctly predicts positives; False Positives (FP), where negatives are incorrectly predicted as positives; True Negatives (TN), where negatives are correctly identified; and False Negatives (FN), where positives are incorrectly identified as negatives. The formulae for calculating these are based on comparing the model's predictions to the actual ground truth.
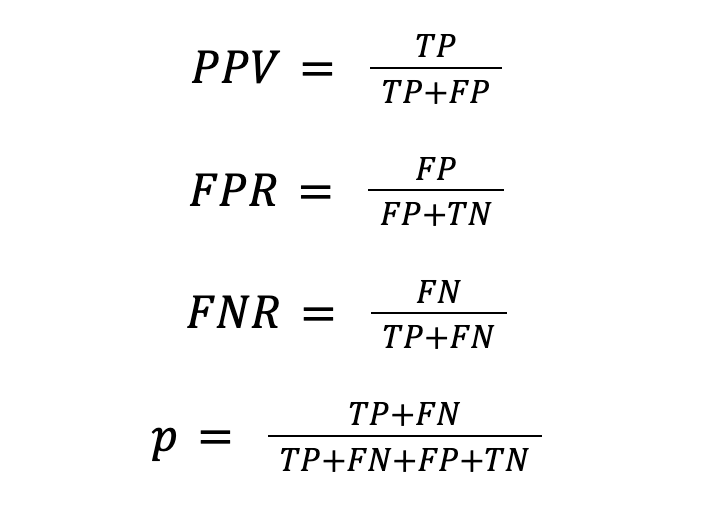
From the confusion matrix, we derive several other important metrics, such as Positive Predictive Value (PPV), False Positive Rate (FPR), False Negative Rate (FNR), and prevalence. PPV, also known as precision, measures the proportion of positive identifications that were correct. FPR measures the proportion of actual negatives that were incorrectly identified as positives. FNR calculates the proportion of real positives that the model failed to detect. Prevalence indicates the actual occurrence rate of the positive class in the dataset.
These metrics are crucial for understanding a classifier's performance, beyond simple accuracy.
Let  be a non-empty set and let
be a non-empty set and let  be functions that classify elements of into positive (
be functions that classify elements of into positive ( ) and negative (
) and negative ( ) classes. We assume that
) classes. We assume that  represents the true, or correct, classification for elements in , whereas
represents the true, or correct, classification for elements in , whereas  is the approximation to the correct classification given by the predictions of an AI model. In this setting, true positives (TP), true negatives (TN), false positives (FP) and false negatives (FN) can be defined as follows:
is the approximation to the correct classification given by the predictions of an AI model. In this setting, true positives (TP), true negatives (TN), false positives (FP) and false negatives (FN) can be defined as follows:

The quantities above are organized into the confusion matrix as follows:

Furthermore, the positive predictive value (PPV), the false positive rate (FPR), the false negative rate (FNR) and the prevalence (p) are derived from the ones above using the following formulae:
In the landscape of AI development, mathematical constraints on what can be achieved in terms of fairness present formidable challenges. Therefore, the fact that several mathematical theorems have been proved that demonstrate the impossibility of an AI system that (under common conditions) simultaneously fulfils multiple fairness definitions is an important barrier.
A key example of such a theorem, detailed further in Sidebar 2, asserts that unless the prevalence is precisely the same across demographic subgroups—an unlikely scenario—no AI model can simultaneously achieve equal positive predictive value, equal false positive rate, and equal false negative rate across the subgroups.
This result highlights the inherent tension between mathematical feasibility and the pursuit of fairness in AI.
Sidebar 2: An Impossibility Theorem for Algorithmic Fairness
To prove a simple version of the impossibility theorem for algorithmic fairness, we need first to provide some additional framework.
First, following the setting provided in Sidebar 1, let us assume that  is a bipartition of —i.e., that
is a bipartition of —i.e., that  and
and  are non-empty subsets of such that
are non-empty subsets of such that  and
and  .
.
and represent subgroups of across which fairness is to be evaluated. For example, and might represent demographic subgroups, one of which is socially disadvantaged.
Note that, separately on and , we can provide the same definitions as in Sidebar 1—for example, we can define:
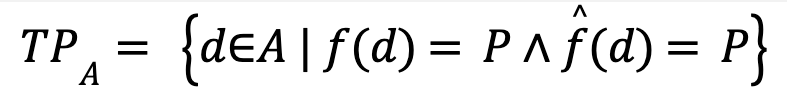
with other quantities defined similarly. In this setting, let us state some often desirable fairness conditions:
Fairness Condition 1 – Predictive Parity: 
Fairness Condition 2 – Classification Parity:  and
and 
Let us also define when a model meets real-world conditions: a model is real-world if it is essentially not a perfect predictor: if  ,
,  ,
,  , and
, and  . Note that almost all models will be real-world under this very weak restriction.
. Note that almost all models will be real-world under this very weak restriction.
Given all the definitions above in mind, we can now state and prove the following result.
Theorem (Impossibility Theorem for Algorithmic Fairness). Any model that is real-world on and , and for which  , cannot simultaneously satisfy both the Predictive Parity and Classification Parity fairness conditions.
, cannot simultaneously satisfy both the Predictive Parity and Classification Parity fairness conditions.
Proof. We prove the contrapositive statement—i.e., we prove that if both Predictive and Classification Parities hold, then it must be the case that  .
.
The key to the proof is the following formula, that holds for all real-world models:

This equality is easily shown using the definition of PPV, and by noting that  , and
, and  , where TPR and FPR are the true positive and false negative rates respectively.
, where TPR and FPR are the true positive and false negative rates respectively.
If we apply such an equation to A and B separately, we have that:
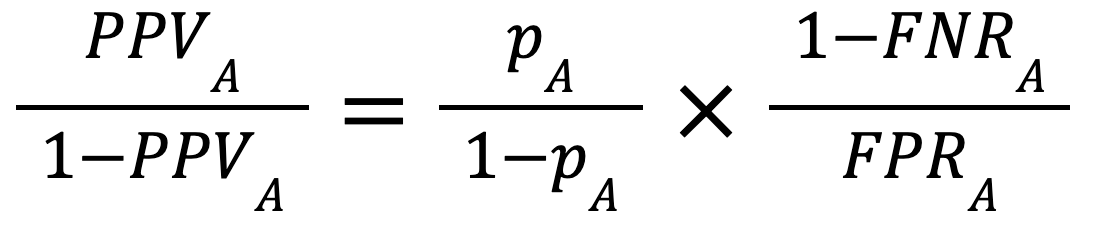
and
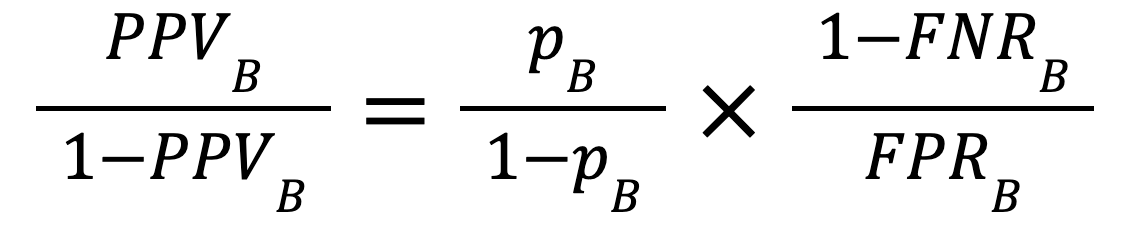
Now, if both Predictive Parity and Classification Parity hold, we also have that:
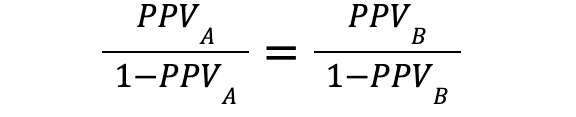
and
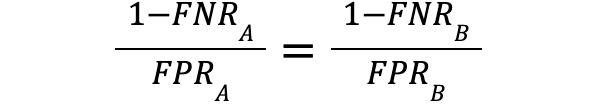
We therefore have that:
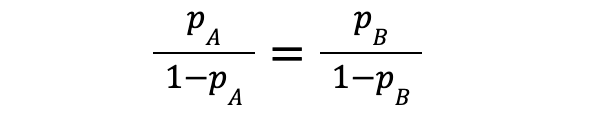
which finally implies that .
Given the mathematical constraints highlighted by impossibility theorems such as that exemplified in Sidebar 2, AI developers face ethical dilemmas in defining fairness. The choice of a fairness definition should be grounded in clearly articulated ethical principles to guide consistent application and decision-making. This approach ensures that despite the impossibility of achieving all fairness metrics simultaneously, the chosen definition aligns with a deliberate ethical stance, addressing specific concerns and values pertinent to the AI system's context and impact on different demographic groups.
Moreover, choosing a fairness definition based on ethical principles ensures AI systems are developed with a conscious understanding of their societal impact. By articulating and adhering to these principles, developers can navigate the inherent limitations imposed by impossibility theorems with transparency and accountability, fostering trust among users and stakeholders. This approach encourages a broader discussion about the values we want AI systems to reflect, promoting a more inclusive and equitable technological future.
Applying Fairness Metrics Across Domains
Let us take these considerations into practical examples, where the fairness condition to be adopted should also be based on domain-specific concerns: referring to Sidebars 1 and 2, in some cases Predictive Parity might be the condition to prioritise, while in other cases Classification Parity might be more important.
An example of the first instance would be an AI system for loan applications: prioritising Predictive Parity in this case aims to ensure that all demographic groups have an equal chance of being correctly identified as likely to repay a loan. This is crucial in financial contexts to avoid systemic discrimination and ensure equitable access to financial services, promoting fairness in opportunities for financial assistance and growth across different societal groups.
On the other hand, in criminal justice risk assessments, prioritising classification parity (equal FPR and FNR across groups) is crucial because it directly impacts individuals' freedom and lives.
By ensuring equal false positive and false negative rates, the system avoids disproportionately labelling individuals from certain demographic groups as likely to reoffend. This is essential for upholding justice and fairness, as it seeks to eliminate systemic biases that could lead to unequal treatment and outcomes in the pretrial process.
The impacts of the choice of a fairness metric varies among stakeholders because each group has different priorities and risks associated with AI decisions. For instance, a metric favouring one group may inadvertently disadvantage another, impacting employment, legal outcomes, or access to services.
Hence, in the decision-making process for implementing conditions of fairness in AI, it is vital to include a wide range of stakeholders, such as the end users affected by the AI system, domain experts who understand the nuances of its application, ethicists, legal advisors, and community representatives.
Involving a diverse pool of stakeholders ensures that multiple perspectives are considered, highlighting potential pitfalls in the chosen fairness definitions, and facilitating the identification of adverse impacts that might not be evident from a narrower viewpoint.
While the involvement of a diverse group in making decisions about fairness definitions in AI is critical for ensuring that these technologies are equitable and beneficial for all sections of society, it is important to keep in mind that the technical nature of AI and its fairness metrics can be a barrier to understanding for non-technical stakeholders, such as end-users or decision-makers without a background in technology.
This gap stresses even more the importance of transparency and interpretability in AI systems.
Communicating Fairness in AI Ethics
To bridge this divide, operational and technical definitions of fairness must be communicated in accessible language. This approach not only demystifies AI for a broader audience but also fosters an inclusive environment where ethical considerations are made transparently.
By prioritising understandability, ethical deliberations around AI are not confined to technical experts but are a collaborative effort, reflecting a wide range of perspectives and values. This inclusivity is fundamental to developing AI systems that are truly fair and ethical, reinforcing the responsibility of developers to engage in clear, open dialogues about the impact and operation of their systems.
With transparency and interpretability in mind, it is also essential that the incorporation of ethical decisions into the choice of fairness metrics is carried out early in the AI development lifecycle. Early engagement ensures that the data collection process for training and testing the AI system is aligned with broad ethical standards.
This pre-emptive approach helps identify and mitigate potential biases at the source, fostering fairness and inclusivity from the ground up. Early intervention also reduces later revisions before the discovered issues become deeply integrated into the system's architecture. As such, this prevents the complex and costly process of reworking or redesigning the system, ensuring that fairness and ethical standards are “hard-wired”, rather than retrofitted, elements of AI development.
Regulations and standards, such as the EU AI Act and ISO/IEC standards provide a crucial foundation for these ethical decision-making processes: indeed, by establishing a set of internationally recognised principles and procedures, regulations and standards provide a structured approach to ethical considerations in AI. This structured approach mandates that developers not only make proactive ethical decisions, but also document these decisions thoroughly, ensuring transparency and accountability.
However, it is worth emphasising that these guidelines do not absolve developers from their responsibility to proactively engage with ethical dilemmas. The essence of the work in AI development transcends mere compliance; it demands a deeper, more proactive engagement with ethical considerations.
The true challenge lies in navigating waters where tough choices are inevitable.
These regulations set the stage, but it is up to the developers and stakeholders to perform. By engaging with a wide range of perspectives, developers have the possibility to understand the many impacts of their work and make decisions that not only comply with established frameworks but also uphold the shared ethical principles that have been established early in the design of the AI system.
This is a task that should be approached with diligence, empathy, and an unwavering commitment to doing what is right.
Disclosure: This article is an advertorial and monetary payment was received from BSI. It has gone through editorial control and passed the assessment for being informative
******
Make sure you check out the latest edition of AI Magazine and also sign up to our global conference series - Tech & AI LIVE 2024
******
AI Magazine is a BizClik brand